

What Are The Cognitive Objectives Of Computer Repair
![]()
A Cognitive Diagnostic Module Based on the Repair Theory for a Personalized User Experience in Eastward-Learning Software
Department of Informatics and Computer Engineering, University of Due west Attica, 12243 Athens, Greece
*
Author to whom correspondence should be addressed.
Academic Editors: Antonio Sarasa Cabezuelo and Covadonga Rodrigo San Juan
Received: 29 September 2022 / Revised: 27 October 2022 / Accustomed: 28 October 2022 / Published: 29 October 2022
Abstruse
This paper presents a novel cerebral diagnostic module which is incorporated in e-learning software for the tutoring of the markup language HTML. The organisation is responsible for detecting the learners' cerebral bugs and delivering personalized guidance. The novelty of this arroyo is that it is based on the Repair theory that incorporates additional features, such as educatee negligence and test completion times, in its diagnostic machinery; also, it employs a recommender module that suggests students optimal learning paths based on their misconceptions using descriptive test feedback and adaptability of learning content. Because the Repair theory, the diagnostic machinery uses a library of error correction rules to explain the cause of errors observed by the educatee during the assessment. This library covers common errors, creating a hypothesis space in that way. Therefore, the test items are expanded, so that they belong to the hypothesis space. Both the system and the cognitive diagnostic tool were evaluated with promising results, showing that they offer a personalized experience to learners.
i. Introduction
During the last decades, Adaptive Educational Hypermedia Systems (AEHS) take prevailed in the field of online learning, since they can course a depiction of each unique user's objectives, interests, and cerebral ability [i]. Moreover, they can be utilized to tailor the learning environment to their needs and preferences. Usually, the students' goal is to larn all the learning textile or at to the lowest degree a meaning part of information technology. That means that students' knowledge level is a determinant for their interaction with the system and information technology can alter based on their functioning [2]. For example, the knowledge level of a user can vary profoundly in comparison to others, but also in other cases, information technology can increase quickly. As such, the same educational material can be vague for a beginner learner and at the aforementioned time picayune and boring for an advanced learner. Moreover, especially for beginners, it needs to exist noted that they start using the organization knowing nothing virtually the specific subject existence taught, and most of the material will lead to subjects that are completely new to them. These users need guidance to find the "right" educational path. The guidance can have the form of diagnosis of misconceptions and/or errors.
Equally mentioned before, the knowledge of the users on the subject seems to exist the most important characteristic for error diagnosis in nigh AEHSs. Near all adaptive presentation techniques, east.yard., fuzzy weights [three,4], artificial neural networks [5,6], multiple-criteria decision analysis [7,8], are based on user noesis equally the main source of personalization. User knowledge is a variable for each user. This ways that an AEHS, existence based on user cognition, must recognize changes in the user knowledge state updating the user model accordingly.
One possible way for depicting the knowledge of students in comparison to the cognition held by the organization is the approach of the overlay modeling. The overlay model is one of the about often used and popular pupil models. It has been proposed by Stansfield et al. [9] and incorporated in several unlike learning technology systems. The overlay model is based on the idea that a learner's knowledge of the domain may exist partial, notwithstanding valid. Every bit a result, the student model is a subset of the domain model [10], which shows expert-level cognition of the subject area [eleven], according to overlay modeling. The discrepancies betwixt the student's and skillful'due south sets of cognition are thought to be due to the student'south lack of skills and noesis, and the instructional goal is to minimize these differences.
A disadvantage of the overlay model is its disability to represent possible misunderstandings (misconceptions) of the user [12]. For this purpose, the buggy model has been proposed representing the user'southward knowledge as the matrimony of a subset of the field of knowledge and a ready of misunderstandings. The buggy model helps to better correct the user's mistakes since the beingness of an image for the incorrect knowledge is very useful from a pedagogical point of view.
In the issues itemize model, there is a large library of predefined misinterpretations that are used to add the relevant misinterpretations to the user model. A disadvantage of this model is the difficulty of creating the library of misinterpretations. The user's misinterpretations are detected during the cess process. Usually the library contains symbolic rules—conditions and actions that are performed when they are activated.
Analyzing the related literature, there is strong prove that the field of error diagnosis in e-learning software has been poorly researched for the learning of different concepts, the most prevalent of which are language learning and reckoner programming. Apropos language learning, there have been several inquiry efforts that nowadays the error diagnosis procedure tin diagnose, amongst others, grammatical, syntactic, vocabulary mistakes past using techniques, such as guess string matching, convolutional sequence to sequence modeling, context representation, etc. [thirteen,14,xv,sixteen,17,18,nineteen]. For example, the work of [nineteen] proposes a sequence-to-sequence learning approach using recurrent neural networks for conducting error analysis and diagnosis. The main idea is that errors may hinder in specific words and with this arroyo, the mistake correction can happen successfully. Some other case is the piece of work of [13]. The authors employed a context representation approach to discover grammatical errors emerging from the vagueness problems of words. In the work of [14], the authors used the Clause Complex model to clarify the learners' errors emerging from grammatical differences in linguistic communication learning. The work of [15] proposes a framework of hierarchical tagging sets to perform annotation of grammatical mistakes in language learning. Finally, the authors of [16] performed nomenclature on spelling mistakes in 2 categories, i.e., orthographic and phonological errors. Concerning estimator programming, the researchers perform error diagnosis for identifying either syntax or logic errors, by employing different intelligent techniques, such equally fuzzy logic, periodical advice delivery about program's beliefs, concept maps, highlighting similarities [20,21,22,23,24,25,26]. Information technology must be noted that all the aforementioned mistakes (e.g., grammatical or vocabulary in language learning systems, and syntax or logical in programming learning systems) may emerge from unlike causes, such as negligence or incomplete knowledge [27,28,29].
From the presented literature review, information technology can be inferred that researchers neglect to fairly blend theories and models with intelligent techniques to back up the process of error diagnosis. In our approach, we employed the Repair theory [30,31] to explain how students can learn with specific attention to the learning manner and the reasons of their misconceptions. To extend the efficiency of the presented module, we incorporated a buggy model, associated to the assessment process. This model holds several possible reasons for learners' misconceptions, such equally carelessness or knowledge deficiency. The novelty of our approach is non only the utilise of buggy modeling based on the Repair theory, but likewise the exploitation of the exported diagnosis for recommending the optimal learning path to students. In particular, the organization using the diagnostic machinery detects the possible reason of students' misconceptions and provides tailored descriptive feedback most the score achieved, the test duration, and the learning path that should be followed in order for the students to better their learning outcomes and knowledge bugs detected.
2. Diagnosis of Student Cerebral Bugs and Personalized Guidance
When evaluating the student performance, the e-learning systems mainly consider but the number of incorrect answers and based on the score accomplished, they construct the student profile [32]. However, this score is not representative of the actual student knowledge and skills, since an incorrect answer does not ever imply a cerebral gap, just it may occur due to student carelessness [33]. As such, the reason why students fail to reply correctly in tests is of great importance in order to provide them the proper guidance for increasing their learning outcomes.
To this direction, the paper presents an integrated student bugs diagnostic mechanism, embodied into an e-learning system, for detecting the student cognitive bugs and providing personalized guidance. The novelty of this approach is that not but is it based on Repair theory incorporating additional features, such as student carelessness and completion fourth dimension of tests, in its diagnostic mechanism, just it likewise recommends to students the optimal learning path according to their misconceptions using descriptive feedback on the examination and adapting learning content.
Because the Repair Theory, the presented diagnostic mechanism uses a buggy rule library to explicate the causes of students' bugs, observed during the assessment process. This library includes the common bugs, creating a hypothesis space in that mode. Hence, the test items are developed in lodge that they appertain to the hypothesis space. The buggy rules were constructed past ten computer science professors in Greek Universities, who have taught the HTML language for at least three years. In particular, they were asked through interviews to describe the well-nigh usual misconceptions the students fabricated during the education of the course. Their answers were recorded and classified, producing a draft version of the buggy rules. In the second round of interviews, the experts were asked to update and/or confirm the rules. This procedure was repeated one more time. After that, the final version of the buggy rules was produced, including 96 potential misconceptions.
The diagnostic mechanism utilizes a repository of tests associated with the course lessons. Each exam consists of a set of questions; each of which is related to a certain concept of the lesson. Every question's answer is characterized by the degree of student carelessness ranging from 0 (indicating a possible knowledge gap) to ane (suggesting a selection by mistake) and the buggy rule explaining the student misconception. Thus, when students give an incorrect answer, the arrangement can detect if at that place is a misconception and in which part of the lesson. Every question item of a test has an alternative one referred to the same concept. Hence, when a student, taking a exam, gives a wrong answer that has a high degree of abandon, the system delivers the alternative question. If the student answers this question correctly, and then the arrangement supposes that the get-go incorrect answer was due to student carelessness. In this case, the mistake is not calculated to the final score and the organisation merely informs the student to be more conscientious. If the student answers incorrectly in the second chance he/she has, then the system assumes that there is a knowledge gap on the concept to which the questions are referred, regardless of their degree of student carelessness. Moreover, the system considers the final score and the completion time of the test in order to provide to students a full report of hints for improving their learning outcomes. Effigy 1 illustrates the entity–relationship model of the diagnostic mechanism. The algorithmic representation of diagnostic mechanism is shown in Algorithm ane.
| Algorithm 1 Diagnostic Mechanism |
| 1: student test time = 0 2: mistakes = 0 iii: start time = time 4: do v: Brandish question(exam) 6: Get answer 7:if is in correct(respond) AND caste of carelessness (answer) < 0.5 then viii: Display alternative question in same concept(test, question) 9:if is correct (reply) then 10: Print "Exist careful with your answers!" eleven:else 12: Get concept, buggy rule related to answer 13: Store concept, buggy rule in student profile 14: mistakes + = 1 15:endif 16:endif 17:if last question (test) and then 18: Student examination time = fourth dimension—start time 19:endif xx: until student test time <> 0 21: educatee test score = Calculate score (mistakes) 22: Print study on score (student test score) 23: Print written report on test elapsing(educatee test fourth dimension) 24: Print report on concepts(pupil contour) 25: Print study on bugs(student contour) |
At the stop of a test, the system provides personalized guidance, which constitutes the optimal learning path that can pb the student to improve his/her performance. This descriptive feedback reports on the following:
-
Success rate on the exam, giving a respective motivation message.
-
Time taken for completing the test, which is compared to the average time all students needed to fill in the test.
-
Concepts in which the pupil had fabricated a mistake that indicated a misconception.
-
The misconceptions detected by the diagnostic mechanism.
Table i depicts the structure and rationale behind the personalized guidance.
3. Examples of Operation
The course that has been chosen for learning through the presented system is the HTML language. The reason for this choice is that although this language can exist characterized as quite like shooting fish in a barrel to learn and to use, it has many peculiarities emerging from the pages' construction and plenty of tags. The HTML elements are blocks, namely tags, written using bending brackets, and may include other tags as sub-elements. Moreover, each element may consist of a number of attributes related to the type of tag. These markups may brand the agreement of the linguistic communication hard, leading to several misconceptions. These bugs in student cognitive country were documented by the experts, based on their experience in educational activity the HTML language. A sample of the buggy rules emerged from this process is illustrated in Table 2.
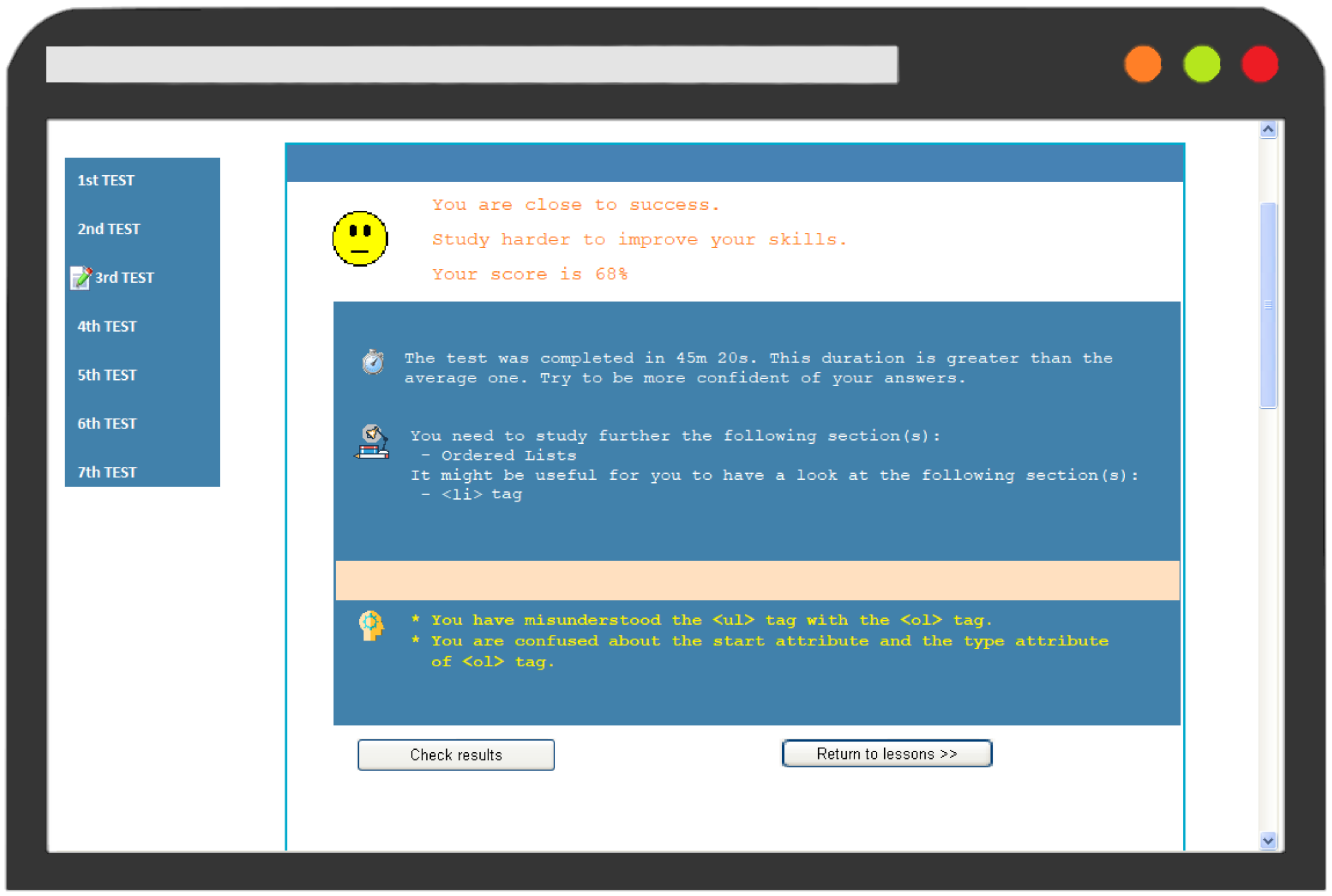
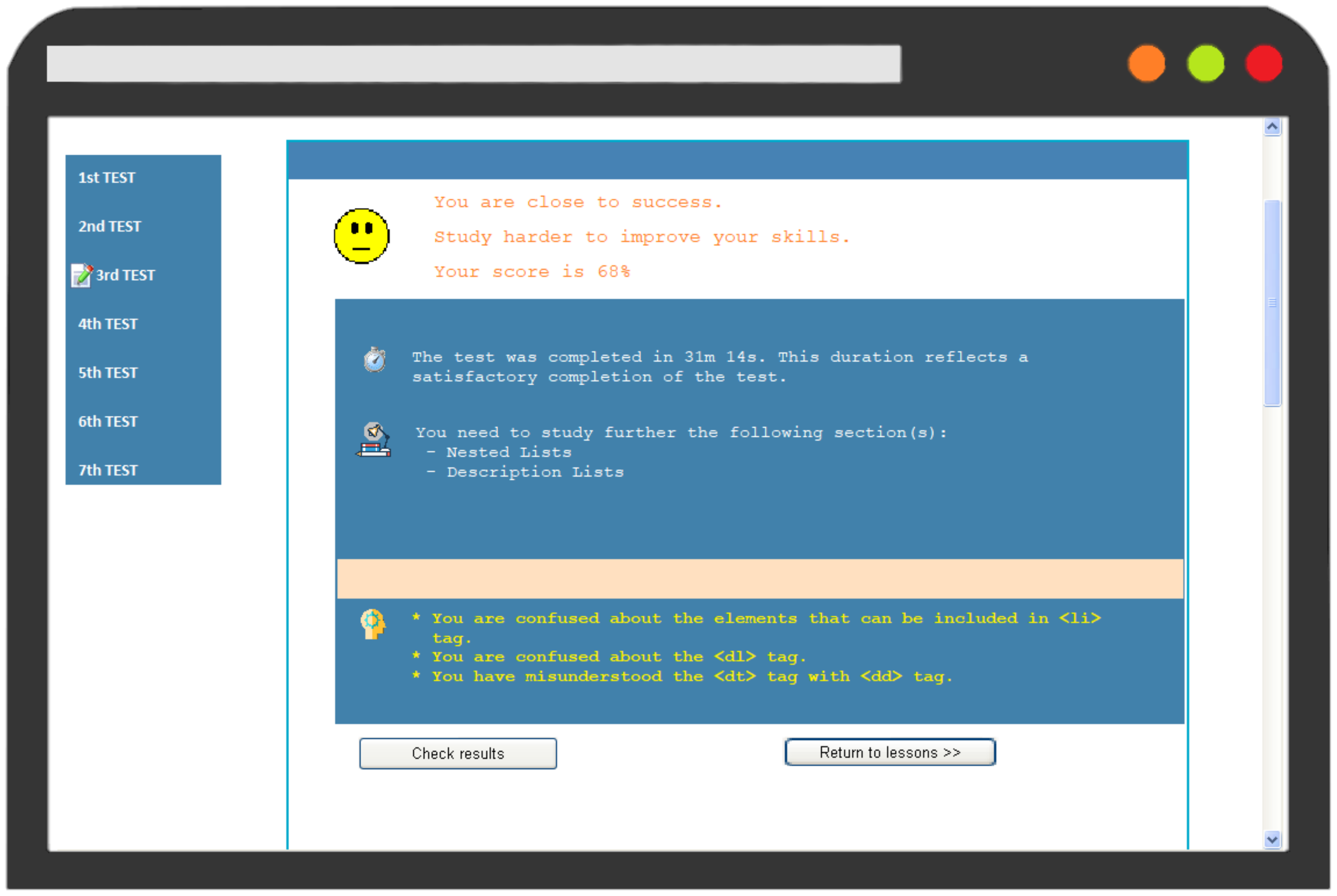
In order to amend empathize the functionality of the diagnostic module and the adaptive feedback delivered, an example of operation is provided comparing the interaction of two users with the system. In detail, Pupil A and Student B took the third Examination which corresponds to the "HTML Lists" lesson. Figure 2 and Figure 3 illustrates their results on the test. Both students reached a score of 68%; even so, they received dissimilar feedback. The organisation stimulates Student A to study farther the "Ordered Lists" and suggests that it might be useful a revision on <li> tag. Student A bugs concern the <ul> and <ol> tags, likewise every bit the start and type attributes of <ol> tag. On the other hand, the organisation recommends that Student B should study "Nested Lists" and "Clarification Lists"; while his misconceptions refer to the <dl>, <dt>, and <dd> tags, as well equally the elements that can exist included in <li> tag.
The reason why the reports to students are dissimilar is that although they made the same number of mistakes, they either gave different incorrect answers on the same question or made mistakes in different questions, referred to unlike sections of the lessons. As such, the system diagnosed different misconceptions and incomplete cognition in sections for each student, providing individualized guidance regarding the learning path that should be followed. Moreover, information technology informed them about the bugs detected, helping them on their better handling.
four. Arrangement Evaluation
For evaluating the presented arrangement, lxxx undergraduate computer science students at a public academy in Greece participated. Students' age ranged from 20 to 21 years onetime, having approximately equal computer skills and knowledge, every bit all of them were at the tertiary year of their studies. Moreover, the sample consists of 44 (55%) male person and 36 (45%) female person students. The students were separated into two groups of 40 members with the same number of males and females, i.e., Group A and Group B.
The evaluation process took place during the tutoring of the "Web Programming" course, for a semester. In particular, Group A was taught the section concerned the "HTML Language" solely using the presented personalized e-learning system; while Group B used a conventional one without diagnosis of pupil bugs or personalization for this purpose. The reason of using the conventional organisation in the evaluation process is for assessing the potential of the cognitive diagnosis and personalized guidance used in our organisation in comparison to conventional approaches. All the students reacted passively to this new learning experience, completing successfully the required tasks/tests without dropouts.
Firstly, the system evaluation pertains to three dimensions, namely the user feel, the effectiveness of personalization and the impact on pupil learning [34]. Hence, a ten-point Likert scale questionnaire was conducted, including iii questions for the cess of the two outset dimensions and four questions for the terminal dimension (Table iii). The questionnaire was delivered to students after the completion of the grade and all of them answered it.
The ten-point Likert scale answers were converted into three categories, namely Depression ranging from 1 to 3, Average ranging from 4 to 7, and Loftier ranging from 8 to ten; and, they were aggregated in the 3 dimensions. Figure four illustrates the evaluation results of Grouping A, concerned its interaction with the presented arrangement, in comparison with Group B, which was interacting with the conventional system. The results reveal that the presented system is superior to the conventional one, regarding the three dimensions of the evaluation.
The "User Experience" of the presented organisation had 86% of high rating, indicating that students had a positive learning experience; whereas, the conventional i was rated 18% for high scores. In improver, 91% of Group A students declared the personalization mechanism was extremely helpful in establishing a learner-centered environment, as emerged past the results of the category "Effectiveness of Personalization". On the other hand, the low rating of Group B in this category indicates the lack of personalization in the conventional system. Finally, unlike the conventional version, the findings for the category "Bear on on Learning" of the presented system are quite encouraging, demonstrating a 88% success charge per unit for our software'southward pedagogical affordance. Analyzing the results of the evaluation research, at that place is potent prove that our presented method can further better the adaptivity and personalization of eastward-learning software by incorporating error diagnosis mechanisms, laying the groundwork for more than individualized tutoring systems.
Secondly, in social club to determine whether the personalization mechanisms used in the presented organization have an effect on students comparing to conventional systems, the two-sample t-test between Group A and Group B was practical in questions iv–half dozen.
Based on the t-exam findings (Table 4), information technology can exist concluded that there is a statistically significant divergence betwixt the means of the two trials when it comes to the same questions (Q4, Q5, Q6). In further detail, the system used by Grouping A was found to detect significantly more appropriately students' misconceptions than the conventional one used past Grouping B (Q4: t(39)= sixteen.19, p <0.05). Moreover, at that place was a meaning difference in the rating of the personalized guidance for Group A (Mean: eight.73, Variance: 2.72) and Group B (Hateful: 5.45, Variance: one.38), where t(39) = 10.78 and p = ii.92 × 10−thirteen (Q5); equally well as, in the relevance of learning content delivered for Group A (Mean: 8.48, Variance: 3.18) and Group B (Mean: five.6, Variance: 1.89), where t(39) = ten.81 and p = 2.7 × 10−13 (Q6). These results advise that the proposed organization outperforms its conventional version in terms of appropriate detection of learners' misconceptions, personalized guidance and delivery of learning content. These outcomes were anticipated, given that the presented organization, based on buggy model and Repair theory, provides tailored feedback to students about their misconceptions and the actions they should take in order to better them. Equally a upshot, a student-centered learning environment is provided, with enhanced knowledge acquisition and learning outcomes. On the other manus, the conventional arrangement only delivers the final score, lacking in descriptive assay of test results and thus, students are totally helpless regarding the learning path they should follow.
Finally, for evaluating the leaning outcomes, the final score of the course, emerged from the average of all capacity' tests, was calculated for each student in Group A and Group B, and the two-sample t-test between the final scores of these ii groups was applied. The goal of this experiment is to investigate whether the students who used the presented arrangement accomplished higher performance than those who used the conventional version.
Analyzing the t-test results on learning outcomes (Table v), information technology can be observed that there is a statistically significant difference between the means of the ii groups. In particular, students who used the presented system had college final scores (Mean: 82.45, Variance: 167.99) than did those using the conventional i (Mean: lxx.05, Variance: 170.05), t(78) = 4.27 and p = v.55 × 10−5. These results suggest that the approaches used for detecting students' misconceptions and for providing the tailored descriptive feedback tin can enhance learning procedure and atomic number 82 students to achieve higher performance.
5. Conclusions
This paper describes a novel cognitive diagnostic module that has been included in an e-learning program for HTML educational activity. The technology is responsible for identifying the learners' cerebral flaws and providing tailored instruction. This approach is unique in that it is based on the Repair theory and incorporates additional features into its diagnostic machinery, such as student negligence and test completion times; it also employs a recommender module that suggests students optimal learning paths based on their misconceptions using descriptive test feedback, equally well every bit the flexibility of learning materials. Using the Repair theory, the diagnostic mechanism explains the source of errors, noticed by the student during the cess. This library covers typical blunders, effectively generating a hypothesis space. As a outcome, the test items are enlarged to include the hypothesis infinite. The buggy rules were developed by a group of informatics academics with a great feel in pedagogy HTML. They were specifically asked through interviews to characterize the most common misconceptions that learners had, during the form's training.
Our approach was fully evaluated using a well-known model and student'south t-test. The results are very promising, showing that the organization assisted students in a loftier degree to better understand their misconceptions. Based on the evaluation results, our approach was reported to have a positive bear upon on learning, to create a personalized learning environment for students and offer an optimal user experience.
Future piece of work includes the extension of the buggy modeling and so that the e-learning software can cope with dissimilar misconceptions and reasons of learners' mistakes. Moreover, future enquiry plans include the alteration of recommendations to learners in terms of level of detail. Finally, part of our future work is to further evaluate the efficiency and acceptance of our system using qualitative techniques, such every bit interviews, and additional quantitative ones, such as pretest-posttest blueprint.
Author Contributions
Conceptualization, A.Grand. and C.T.; methodology, A.Grand. and C.T.; validation, A.K. and C.T.; formal assay, A.K. and C.T.; investigation, A.K. and C.T.; resources, A.K. and C.T.; data curation, A.K. and C.T.; writing—original typhoon training, A.1000. and C.T.; writing—review and editing, A.G. and C.T.; visualization, A.K. and C.T.; supervision, C.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study at the fourth dimension of original information collection.
Data Availability Statement
The data used to support the findings of this study take not been made available because they contain data that could compromise research participant privacy/consent.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Somyürek, S. The new trends in adaptive educational hypermedia systems. Int. Rev. Res. Open Distrib. Larn. 2015, xvi. [Google Scholar] [CrossRef]
- Somyürek, Southward.; Brusilovsky, P.; Guerra, J. Supporting knowledge monitoring ability: Open up learner modeling vs. open social learner modeling. Res. Pract. Technol. Enhanc. Learn. 2020, xv, 1–24. [Google Scholar] [CrossRef]
- Troussas, C.; Krouska, A.; Sgouropoulou, C. Collaboration and fuzzy-modeled personalization for mobile game-based learning in college education. Comput. Educ. 2020, 144, 103698. [Google Scholar] [CrossRef]
- Cuong, B.C.; Lich, N.T.; Ha, D.T. Combining Fuzzy Set—Unproblematic Additive Weight and Comparing with Gray Relational Analysis For Student'south Competency Assessment in the Industrial 4.0. In Proceedings of the 2022 10th International Conference on Noesis and Systems Engineering science (KSE), Ho Chi Minh City, Vietnam, 1–3 Nov 2022; pp. 294–299. [Google Scholar]
- Saad, M.B.; Jackowska-Strumillo, L.; Bieniecki, West. ANN Based Evaluation of Student'south Answers in E-tests. In Proceedings of the 2022 11th International Briefing on Homo Organisation Interaction (HSI), Gdansk, Poland, iv–six July 2022; pp. 155–161. [Google Scholar]
- Troussas, C.; Krouska, A.; Virvou, Thousand. A multilayer inference engine for individualized tutoring model: Adapting learning material and its granularity. Neural Comput. Appl. 2021, 1–15. [Google Scholar] [CrossRef]
- Troussas, C.; Krouska, A.; Sgouropoulou, C. Improving Learner-Reckoner Interaction through Intelligent Learning Material Delivery Using Instructional Design Modeling. Entropy 2021, 23, 668. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.-M.; Hsieh, M.Y.; Usak, K. A Multi-Criteria Study of Controlling Proficiency in Student's Employability for Multidisciplinary Curriculums. Mathematics 2020, 8, 897. [Google Scholar] [CrossRef]
- Stansfield, J.C.; Carr, B.; Goldstein, I.P. Wumpus Advisor I: A First Implementation of a Program that Tutors Logical and Probabilistic Reasoning Skills; Massachusetts Establish of Technology: Cambridge, MA, United states, 1976. [Google Scholar]
- Martins, A.C.; Faria, L.; de Carvalho, C.V.; Carrapatoso, Eastward. User modeling in adaptive hypermedia educational systems. Educ. Technol. Soc. 2008, 11, 194–207. [Google Scholar]
- Liu, Z.; Wang, H. A Modeling Method Based on Bayesian Networks in Intelligent Tutoring Organisation. In Proceedings of the 2007 11th International Briefing on Reckoner Supported Cooperative Piece of work in Design, Melbourne, Commonwealth of australia, 26–28 Apr 2007; pp. 967–972. [Google Scholar]
- Qodad, A.; Benyoussef, A.; El Kenz, A.; Elyadari, Thou. Toward an Adaptive Educational Hypermedia Arrangement (AEHS-JS) based on the Overlay Modeling and Felder and Silverman's Learning Styles Model for Task Seekers. Int. J. Emerg. Technol. Learn. 2020, 15, 235–254. [Google Scholar] [CrossRef]
- Zhao, J.; Li, M.; Liu, Westward.; Li, Southward.; Lin, Z. Detection of Chinese Grammatical Errors with Context Representation. In Proceedings of the 2022 International Conference on Network Infrastructure and Digital Content (IC-NIDC), Guiyang, Communist china, 22–24 August 2022; pp. 25–29. [Google Scholar]
- Lin, X.; Ge, Due south.; Song, R. Error analysis of Chinese-English language machine translation on the clause-complex level. In Proceedings of the 2022 International Conference on Asian Language Processing (IALP), Singapore, five–7 December 2022; pp. 185–188. [Google Scholar]
- Lee, 50.-H.; Chang, L.-P.; Tseng, Y.-H. Developing learner corpus notation for Chinese grammatical errors. In Proceedings of the 2022 International Conference on Asian Language Processing (IALP), Tainan, Taiwan, 21–23 November 2022; pp. 254–257. [Google Scholar]
- Haridas, M.; Vasudevan, Northward.; Nair, G.J.; Gutjahr, G.; Raman, R.; Nedungadi, P. Spelling Errors by Normal and Poor Readers in a Bilingual Malayalam-English Dyslexia Screening Examination. In Proceedings of the 2022 IEEE 18th International Conference on Avant-garde Learning Technologies (ICALT), Mumbai, Bharat, nine–13 July 2022; pp. 340–344. [Google Scholar]
- Troussas, C.; Chrysafiadi, Chiliad.; Virvou, M. Machine Learning and Fuzzy Logic Techniques for Personalized Tutoring of Strange Languages. In Proceedings of the International Conference on Artificial Intelligence in Education, London, UK, 27–30 June 2022; pp. 358–362. [Google Scholar]
- Khodeir, N.A. Constraint-based and Fuzzy Logic Student Modeling for Arabic Grammar. Int. J. Comput. Sci. Inf. Technol. 2020, 12, 35–53. [Google Scholar] [CrossRef]
- Li, South.; Zhao, J.; Shi, Thousand.; Tan, Y.; Xu, H.; Chen, Yard.; Lan, H.; Lin, Z. Chinese Grammatical Mistake Correction Based on Convolutional Sequence to Sequence Model. IEEE Access 2019, seven, 72905–72913. [Google Scholar] [CrossRef]
- Henley, A.Z.; Ball, J.; Klein, B.; Rutter, A.; Lee, D. An Inquisitive Code Editor for Addressing Novice Programmers' Misconceptions of Program Behavior. In Proceedings of the 2022 IEEE/ACM 43rd International Conference on Software Engineering: Software Technology Education and Training (ICSE-SEET), Madrid, Kingdom of spain, 25–28 May 2022; pp. 165–170. [Google Scholar]
- Lai, A.F.; Wu, T.T.; Lee, Thousand.Y.; Lai, H.Y. Developing a web-based simulation-based learning arrangement for enhancing concepts of linked-list structures in data structures curriculum. In Proceedings of the 2022 tertiary International Briefing on Bogus Intelligence, Modelling and Simulation (AIMS), Kota Kinabalu, Malaysia, 2–4 Dec 2022; pp. 185–188. [Google Scholar]
- Chang, J.-C.; Li, S.-C.; Chang, A.; Chang, G. A SCORM/IMS Compliance Online Test and Diagnosis Organisation. In Proceedings of the 2006 7th International Conference on Information technology Based Higher Educational activity and Grooming, Ultimo, Australia, 10–xiii July 2006; pp. 343–352. [Google Scholar]
- Barker, S.; Douglas, P. An intelligent tutoring arrangement for plan semantics. In Proceedings of the International Conference on It: Coding and Computing (ITCC'05), Las Vegas, NV, USA, four–6 April 2005; Volume one, pp. 482–487. [Google Scholar]
- Khalife, J. Threshold for the introduction of programming: Providing learners with a simple computer model. In Proceedings of the 28th International Conference on Information Technology Interfaces, Cavtat, Croatia, 19–22 June 2006; pp. 71–76. [Google Scholar]
- Troussas, C.; Krouska, A.; Virvou, Thousand. Injecting intelligence into learning management systems: The case of adaptive grain-size pedagogy. In Proceedings of the 2022 10th International Conference on Information, Intelligence, Systems and Applications (IISA), Patras, Hellenic republic, fifteen–17 July 2022; pp. 1–vi. [Google Scholar]
- Krugel, J.; Hubwieser, P.; Goedicke, M.; Striewe, G.; Talbot, M.; Olbricht, C.; Schypula, M.; Zettler, S. Automatic Measurement of Competencies and Generation of Feedback in Object-Oriented Programming Courses. In Proceedings of the 2022 IEEE Global Engineering science Education Conference (EDUCON), Porto, Portugal, 27–30 Apr 2022; pp. 329–338. [Google Scholar]
- Almeda, Grand. Predicting Pupil Participation in Stalk Careers: The Role of Touch and Engagement during Eye School. J. Educ. Data Min. 2020, 12, 33–47. [Google Scholar]
- Sumartini, T.South.; Priatna, N. Place student mathematical understanding ability through direct learning model. J. Phys. Conf. Ser. 2018, 1132, 012043. [Google Scholar] [CrossRef]
- Troussas, C.; Krouska, A.; Sgouropoulou, C. A Novel Teaching Strategy Through Adaptive Learning Activities for Reckoner Programming. IEEE Trans. Educ. 2021, 64, 103–109. [Google Scholar] [CrossRef]
- Brown, J.; VanLehn, K. Repair Theory: A Generative Theory of Bugs in Procedural Skills. Cogn. Sci. 1980, 4, 379–426. [Google Scholar] [CrossRef]
- Brown, J.Due south.; Burton, R.R. Diagnostic models for procedural bugs in basic mathematical skills. Cogn. Sci. 1978, ii, 155–192. [Google Scholar] [CrossRef]
- Rashid, T.; Asghar, H.M. Technology utilise, self-directed learning, educatee engagement and academic operation: Examining the interrelations. Comput. Hum. Behav. 2016, 63, 604–612. [Google Scholar] [CrossRef]
- Krouska, A.; Troussas, C.; Sgouropoulou, C. Fuzzy Logic for Refining the Evaluation of Learners' Functioning in Online Engineering Education. Eur. J. Eng. Res. Sci. 2019, 4, 50–56. [Google Scholar] [CrossRef]
- Alepis, Due east.; Troussas, C. Chiliad-learning programming platform: Evaluation in elementary schools. Informatica 2017, 41, 471–478. [Google Scholar]
Effigy 1. Entity-Human relationship model.
Figure 1. Entity-Relationship model.

Effigy ii. Feedback to Pupil A on tertiary Test.
Effigy ii. Feedback to Student A on third Test.
Effigy 3. Feedback to Pupil B on third Test.
Figure iii. Feedback to Student B on third Test.
Effigy iv. Evaluation results.
Figure 4. Evaluation results.

Table i. The structure and rationale of the personalized guidance.
Table 2. A sample of buggy rules.
Table 2. A sample of buggy rules.
| Buggy Rules | |
|---|---|
| 1 | Y'all take misunderstood the tag "<" with "#". |
| ii | You take dislocated the trunk department with the head section. |
| 3 | Y'all are dislocated near the i tag and the b tag. |
| 4 | You lot have misunderstood the aspect face of font tag. |
| 5 | You accept dislocated the p tag with the paragraph tag. |
| vi | Yous have confused the <ol> tag with the <ul> tag. |
| 7 | You are dislocated near the start aspect and the type attribute of <ol> tag. |
| 8 | You are dislocated about the <ul> tag. |
Table 3. Questionnaire of system evaluation.
Tabular array 3. Questionnaire of system evaluation.
| Dimension | Questions | |
|---|---|---|
| User Experience | 1 | Charge per unit the user interface of the system. (1–x) |
| 2 | Rate your learning experience. (1–ten) | |
| iii | Did you lot similar the interaction with the arrangement? (1–x) | |
| Effectiveness of personalization | 4 | Did the arrangement notice accordingly your misconceptions? (1–10) |
| 5 | Charge per unit the manner the personalized guidance was presented. (1–x) | |
| six | Rate the learning content relevance to your personal profile. (ane–10) | |
| Affect on Learning | vii | Would yous similar to apply this platform in other courses as well? (1–10) |
| 8 | Did you notice the software helpful for your lesson? (1–10) | |
| nine | Would you propose the software to your friends to utilise it? (1–10) | |
| 10 | Rate the easiness in interacting with the software. (1–10) |
Table 4. T-test results on Q4, Q5, and Q6.
Table four. T-test results on Q4, Q5, and Q6.
| Q4 | Q5 | Q6 | ||||
|---|---|---|---|---|---|---|
| Group A | Group B | Group A | Group B | Group A | Group B | |
| Mean | 8.65 | 5.23 | 8.73 | 5.45 | 8.48 | 5.vi |
| Variance | iii.36 | ii.18 | 2.72 | one.38 | three.18 | ane.89 |
| Observations | 40 | 40 | forty | 40 | 40 | 40 |
| Pooled Variance | 0.69 | 0.11 | 0.46 | |||
| Hypothesized Mean Difference | 0 | 0 | 0 | |||
| Degree of Freedom | 39 | 39 | 39 | |||
| t Stat | 16.19 | 10.78 | 10.81 | |||
| P(T ≤ t) ii-tail | 6.58 × ten−19 | 2.92 × x−thirteen | 2.7 × ten−13 | |||
| t Critical 2-tail | ii.023 | 2.023 | 2.023 | |||
Table 5. T-examination results on learning outcomes.
Tabular array 5. T-test results on learning outcomes.
| Learning Outcomes | ||
|---|---|---|
| Group A | Group B | |
| Mean | 82.45 | 70.05 |
| Variance | 167.99 | 170.05 |
| Observations | xl | forty |
| Pooled Variance | 169.02 | |
| Hypothesized Hateful Deviation | 0 | |
| Degree of liberty | 78 | |
| t Stat | 4.27 | |
| P(T ≤ t) two-tail | 5.55 × 10−v | |
| t Critical two-tail | 1.99 | |
| Publisher's Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open up access article distributed under the terms and conditions of the Creative Commons Attribution (CC By) license (https://creativecommons.org/licenses/by/4.0/).

What Are The Cognitive Objectives Of Computer Repair,
Source: https://www.mdpi.com/2073-431X/10/11/140/htm
Posted by: phelpsafterew.blogspot.com
0 Response to "What Are The Cognitive Objectives Of Computer Repair"
Post a Comment